
BITTENSOR: THE INTELLIGENCE OLYMPICS

Feb 19, 2026
NOTE FOR READER: Khala Research is developing a systematic subnet risk scoring framework to help allocators evaluate subnet investment quality at scale. For any parties interested, please get in touch with the Khala Research team to discuss.
KEY TAKEAWAYS
Artificial Intelligence (AI) development is increasingly centralized, closed, and extractive. A handful of frontier labs (OpenAI, Google, Anthropic, Meta) control the most capable models, the data pipelines, the compute infrastructure, and the economic upside.
Bittensor's answer: a decentralized network that turns intelligence into a commodity that's openly priced, competitively produced, and cryptographically verified.
Enter the 'Intelligence Olympics'.
The network has evolved from a set of experimental incentives into functioning AI infrastructure with paying customers. The ecosystem now shows:
Fiat revenue at scale: Chutes running $5.5M+ annualized.
Signed enterprise contracts: Reading FC, 3,000+ AVIA petrol stations, $10b+ market cap payments companies (under NDA).
Institutional capital entering: Grayscale Trust products, DCG's Yuma receiving financing from Connecticut Innovations (CT’s state VC fund), TAO ETPs.
Academic validation: Templar's SparseLoCo accepted at NeurIPS OPT2025.
Technical milestones: largest permissionless pre-training run ever conducted.
Subnets are generating revenue, serving enterprise clients, and producing research that passes academic peer review.
Real customers are paying real money. That changes the risk profile with proven traction to the ecosystem's long term viability, providing asymmetric upside for those allocating capital.
EXECUTIVE SUMMARY
Each generation of large language models (LLMs) has cost more to train:
In 2020, OpenAI trained GPT-3 for roughly $5M. It was the best language model in the world.
By 2023, GPT-4 cost somewhere between $50M and $100M.
Today, frontier models range in estimates from $500M to over $1B.
The barrier to competitive AI compounds every year, in favor of incumbents.
For investors, the access problem is real: the largest technology opportunity of the generation is either private, priced into mega-caps, or funneling through a single chipmaker (Nvidia).
Bittensor offers a different architecture. Rather than centralizing AI development, it creates an open marketplace where 128 independent subnets compete to produce AI services, earning TAO based on output quality. We call it the Olympics for AI.
Over the past year, the network crossed from experiment to commercial traction: enterprise contracts, institutional capital entering, and the first halving tightening supply. This report profiles five subnets demonstrating that transition.
1. THE CONCENTRATION PROBLEM AND CRYPTO'S SOLUTION
Five companies control the foundation models that will underpin the next decade of software: OpenAI, Google, Anthropic, Meta, and Microsoft.
Between them, they command the talent pipelines, the GPU allocations, the data partnerships, and the distribution. Everyone else builds on their infrastructure, at their margins, on their terms. That's the game though, and Bittensor is trying to change the rules.
Crypto was supposed to be good at this. Permissionless coordination, global capital formation, incentive alignment without gatekeepers. For years, it wasn't. Decentralized compute projects struggled to generate revenue. AI agent frameworks came and went. Token-incentivized data networks remained early.
That's starting to change. Decentralized training compute is now growing significantly faster than centralized infrastructure, and the gap is closing quicker than most realize.
Bittensor is leading that shift. The thesis: token incentives can disaggregate AI development entirely. Instead of one lab training one model, a global network of miners contributes specialized capabilities and gets paid based on output. If you can produce value, you can earn TAO. The structural edge is:
Permissionless participation - anyone can contribute if they deliver.
Continuous competition - underperformers lose emissions to those who produce.
Token-based capital efficiency - no Series C required to scale.
These apply whether the subnet is training models, running inference, or discovering drug compounds.
Over the past year, the network matured. Dynamic TAO made subnets directly investable. The first halving tightened supply. Multiple subnets crossed from pilots to contracts. Institutional capital followed: Grayscale's ETF filing, Deutsche Digital Assets' ETP, DCG-backed Yuma launching a subnet fund.
Bittensor is no longer a bet on whether decentralized AI coordination can work. It's a bet on how big the market becomes, and there's a plethora of subnets primed to break out into the real world:
![[share]](https://framerusercontent.com/images/iXnVvfjWbR2fdFevvc1VGZNCZIA.png)
2. UNDERSTANDING THE SUBNET ECONOMY
If Bittensor is the 'Olympics for AI', subnets are the individual events.
Each subnet operates as its own competition with its own validators, miners, and emission share. To evaluate them, it helps to understand where they sit in the value chain.
Pre-training builds foundation models from scratch. Capital-intensive, technically demanding, highest potential moat.
Inference deploys trained models at scale. Thinner margins, but immediate feedback: serve good inference at competitive prices or you don't earn.
Specialized applications target vertical markets like computer vision, compliance testing, drug discovery. Competing on use-case depth rather than general capability.
The five subnets in this report span all three layers. We picked them for technical edge, commercial traction, and market size.
3. THE CURRENT BITTENSOR LANDSCAPE
Asset managers and capital allocators we've spoken with describe Bittensor as one of crypto's most ambitious and least understood ecosystems.
Over the past 12 months, Bittensor have grown to 128 independent subnets. The network is now generating real fiat revenue (Chutes alone with $5.5M annualized), attracting institutional capital (Yanez via DCG's Yuma, Deep Ventures), and signing enterprise customers across multiple verticals (SCORE via Reading FC, AVIA).
Since $TAO's TGE in 2023, Bittensor's economic model has begun to prove its genesis mission: an incentive framework to coordinate global AI talent to solve global problems.
![[share]](https://framerusercontent.com/images/ZocWqI410eztcwA6S6UuU3xl6iU.png)
4. COVERAGE OF SUBNETS
4.1 SN44 – SCORE
Computer vision is one of the largest addressable markets in AI. Score (SN44) is Bittensor's attempt to decentralize it
AT A GLANCE
Category: Specialized Application (Computer Vision).
Status: Revenue-generating, signed multiple enterprise customers.
Key Customers: Reading FC, AVIA (3k+ stations), Lavance (7k+ stations).
Differentiator: 10-100x cost reduction claim vs. centralized providers.
Watch For: Multi-year contract conversions, ARR disclosure.
Strategic Positioning
Computer vision is a massive untapped data pipeline. Billions of cameras generate footage every day, but extracting intelligence from video still demands proprietary hardware or expensive cloud compute from Google, Nvidia, and AWS.
The cases span petrol station safety, agricultural QC, fleet operations, and sports analytics, yet costs remain prohibitive. A single football match still costs hundreds of dollars to annotate.
SCORE believes they can collapse this cost by 10–100x via Bittensor's miner network. Any camera feed becomes structured data at a price centralized providers can't touch.
Subnet Context
SCORE’s Manako AI is a vision-language platform that converts live video into structured, queryable datasets, comparable to platforms like Google’s AutoML, NVIDIA’s Cosmos VLM, and Roboflow
These competitors are developer-oriented tools for building and deploying computer vision over camera feeds, each typically addresses a specific stage of the workflow.
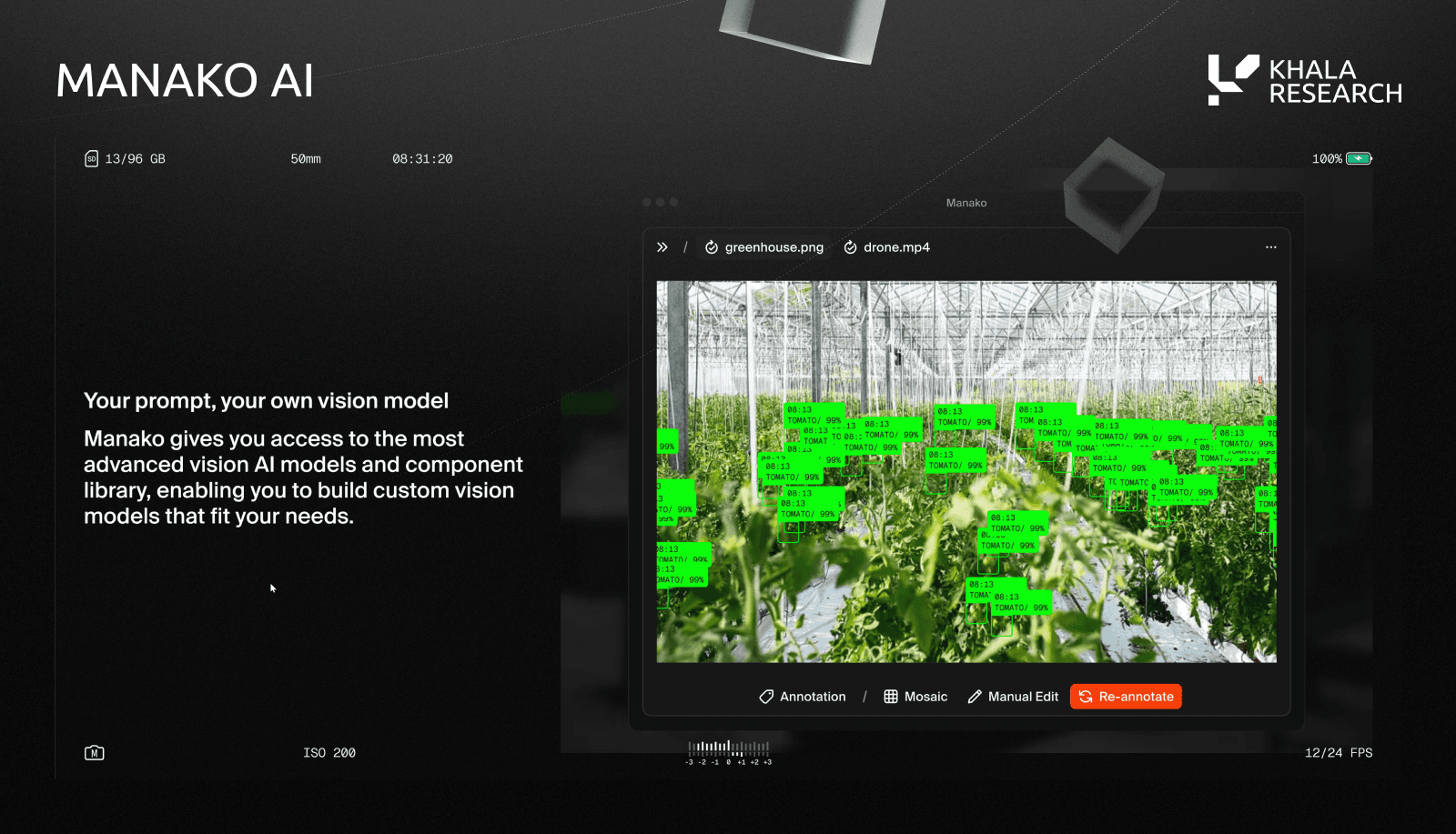
Manako has a broader focus.
Subnet 44 continuously trains base models and supports edge-case competitors on top of those foundations. Performance improves over time across diverse real-world scenarios. The economic incentives on Bittensor expand use-cases organically, rather than relying on a centralized, static, tool-based pipeline.
Over the last three months, SCORE has signed paying customers across various industries:
Reading FC for player data analytics.
AVIA for 3k+ petrol stations.
Lavance for 7k+ vehicle wash stations.

Mechanism Design
Bittensor enables a unique differentiator for SCORE. Manako handles core inference workloads with its own internal model, processing standard object detection, classification, and monitoring across customer deployments.
Bittensor support the edge cases: think unusual lighting, rare objects, and domain-specific scenarios. These are routed to SN44's decentralized miner network, where miners compete to expand the models capabilities (and are rewarded with TAO).
This creates a flywheel. Each new customer deployment surfaces new edge cases. Each edge case sharpens the miner network. Each improvement makes Manako more reliable and more valuable, making it easier to sign the next customer.
Competitive Landscape
No competitor currently offers a decentralized, incentive-driven vision platform spanning multiple verticals at SCORE's claimed price point.
Google AutoML and Amazon Rekognition offer broad cloud APIs but are image-first, require custom pipeline engineering for continuous video, and scale costs linearly/call.
Nvidia Cosmos operates at a different stack layer, providing open-weight foundation models that miners might use, while SN44 is the marketplace that rewards the output.
Stats Perform / Opta and Hawk-Eye / Sony dominate sports analytics but are priced out of the long tail. $100K+/yr licences and proprietary camera installs make lower-tier and non-sports use cases uneconomic.
![[share]](https://framerusercontent.com/images/Ip3ZzK6VDp7nzLvIcH3si93TfQ.png)
Structural Advantages
Each customer surfaces edge cases routed to miners for competitive resolution. Improvements feed back automatically. Quality compounds with usage, not headcount.
Works from existing broadcast footage or standard CCTV. No proprietary camera installations required (vs. competitors, which may require multi camera rights per venue). The multi-vertical customer base validates this.
Risk Factors
100% trial conversion is encouraging, but converting 60-day trials to multi-year contracts with guaranteed SLAs is where most B2B startups stall; No formal ARR disclosures; 10 to 100x cost reduction claim is also self-reported and unaudited.
Stats Perform, Google, and Amazon can all move down-market. Opta Vision (launched 2022) already combines event and tracking data.
Outlook
Real product, real customers, active miner network. The flywheel is turning.
The Vision AI market is early and fragmented: no dominant platform has emerged for turning the world's camera infrastructure into intelligent data streams.
4.2 SN54 – MIID
Stress-testing financial defences using decentralized adversarial AI

AT A GLANCE
Category: Specialized Application (Compliance/RegTech).
Status: Revenue-generating, 3 enterprise clients + 20 claimed pipeline.
Backing: Yuma-incubated, $900k seed (Deep Ventures).
Differentiator: Continuous adversarial testing vs. static vendor datasets.
Watch For: Named client disclosures, revenue reinvestment mechanisms.
Strategic Positioning
Financial institutions spend billions annually on compliance systems (eg: KYC/AML) rarely tested under real attack conditions. Narrow pen testing, static rules, limited adversarial exposure. Most institutions can't prove their defenses actually work.
SN54 MIID (Multimodal Inorganic Identities Dataset) by Yanez Compliance is one of the few subnets with pre-existing enterprise customers and fiat revenue, yet it's received minimal attention from the broader TAO community.
Incubated by Yuma and backed by a $900k seed round with Deep Ventures as an institutional investor, MIID is the decentralized alternative to legacy compliance testing.
Subnet Context
Launched in June 2025, the MIID subnet generates synthetic identities and adversarial scenarios used to stress-test and benchmark real-world KYC, AML, and digital identity defenses, effectively red-teaming sanctions screening systems for traditional financial services institutions.
Bittensor helps MIID scale globally as a token-incentivized red team for financial crime prevention.

Mechanism Design
Miners produce variations of IDs (name transliterations, deepfake biometrics, etc.).
Validators evaluate how effectively submissions expose weaknesses in existing detection systems, rewarding miners based on bypass success, detection latency, and adversarial realism.
The output is sold to financial institutions to harden their defenses; the Bittensor distributed network generates realistic, jurisdiction-specific identity variations across documents, biometrics, and behavioral patterns in regions such as the US, Asia, and Africa at a scale and diversity a centralized team cannot match.
Yanez reinvests a portion of commercial revenue into subnet incentives, but actual percentages or on-chain mechanisms have NOT been published as of Feb 17.
![[share]](https://framerusercontent.com/images/vUEQtU249P6LX63fdfQvzTR8IQ.png)
Macrocosmos explained MIID best as “delivering continuous adversarial data... creating an 'attacker-versus-defender' dynamic that mirrors the real environment far better than static vendors."
Competitive Landscape
The compliance data market is dominated by slow, centralized vendors. LSEG/Refinitiv World-Check and LexisNexis update their datasets periodically, which means every time a new sanctions evasion technique emerges, there's a gap between the attack and the response.
That delta is the vulnerability where financial crime happens.
Fraud-and-identity platforms like SentiLink and Sardine sit on the other side: they detect synthetic or stolen identities in production. Useful, but ultimately, reactive by design.
MIID counterpositions by generating adversarial data specifically for stress-testing. It attacks the systems rather than running detection itself.
Structural Advantages
Sanctions screening and KYC testing are regulatory requirements, not optional spend. Compliance budgets are sticky and recession-resistant.
More clients, more penetration testing use-cases deepens capability network; which then enables a higher quality offering for clients.
Risk Factors
Three primary enterprise clients, with additional 20+ clients claimed in the pipeline. However, all un-named. Enterprise sales cycles in regulated finance typically run 6-18 months. Pipeline conversion data will be key.
$900K total fundraising is thin for enterprise sales into regulated finance.
Revenue reinvestment into the subnet is described in general terms ("periodic funding injections or buy-backs") with no published mechanisms.
Outlook
MIID has real enterprise traction. Bittensor's incentive structure lets them stress-test at a scale no internal team could match. Financial crime prevention is a lucrative, sticky market. Compliance spend doesn't disappear in downturns.
For Yanez, their challenge now is to convert this pipeline and scale these relationships.
4.3 SN68 – NOVA
Decentralized Drug Discovery. Mining for Molecules Instead of Hashes

AT A GLANCE
Category: Specialized Application (Drug Discovery).
Status: Pre-revenue, wet-lab validation expected Q1-Q2.
Key Metric: 418% improvement in hit quality over baseline.
Partnerships: MOU with Yalotein Bio for nanobody testing.
Differentiator: 24/7 global competition vs. 9-5 lab teams.
Watch For: Wet-lab validation results, first licensing deal.
Strategic Positioning
The business of drug discovery is often binary: succeed and your drug is worth billions, fail and it’s worth zero.
If a compound is approved it can generate billions in licensing revenue, but 90%+ of candidates fail in clinical trials (costs can exceed $2.6B and up to 10 years to take a drug to market).
Metanova (SN68) is building a collective intelligence platform to accelerate drug discovery.
Subnet Context
Unlike traditional pharma companies, where they are valued by percentage conversion of drugs in a pipeline, Metanova operates in the earliest stage: leveraging compute, chemical search algorithms, and competitive modeling to identify novel compounds. Metanova runs two competition formats:
Compound challenges miners to submit candidate molecules for defined protein targets.
Blueprint challenges miners to submit search algorithm code that explores chemical space more efficiently.
Both tracks create a feedback loop. Better algorithms improve the molecule discovery engine over time.
NOVA is in the business of discovering net new therapeutic candidates and early-stage drug leads.
This is done via decentralized, 24/7 competitive hackathon where quantitatively skilled miners from fields such as quantitative finance, aerospace, and computational biology generate synthesizable molecules and search algorithms against defined pharmaceutical targets, initially focused on psychiatric and CNS indications. Top performers connect to external labs and CRO partners for validation.
![[share]](https://framerusercontent.com/images/BUW76nURtwnMXNs5M9QquuAqK58.png)
Think Recursion or Insilico, but open-sourced. Metanova crowdsources molecular design through Bittensor rather than building proprietary R&D teams, positioning Metanova as a decentralized virtual biotech that crowdsources molecular design and search algorithms. It also offers drug screening as a service and lets pharma companies stress-test their own models against NOVA's competitive environment.
Mechanism Design
NOVA is reporting 418% improvement in hit quality over baseline via their miners:
Each challenge is tied to a specific protein target.
Miners submit synthesizable candidate molecules generated from a hybrid chemical universe combining the SAVI-2020 database and five combinatorial reaction templates, (mimicking real-world synthesis).
Only one active submission per miner is allowed at a time, creating a winner-takes-all dynamic that rewards genuine innovation over volume.
Competitive Landscape
![[share]](https://framerusercontent.com/images/0wVNFUSwegcSgKxozY8EYNw39FE.png)
Pharma is in a battle of R&D
Centralized competitors are capital-intensive: Recursion ($2.1B market cap, $500M+ cash burn), Insilico Medicine ($500M cumulative raises), Absci (~$380M, multiple Phase 1 candidates). The market leader is Isomorphic Labs (Alphabet/DeepMind), with ~$3B in pharma partnerships and $600M raised in March 2025.
Structural Advantages
Near-zero marginal screening cost vs. centralized R&D burning millions.
Generates molecular assets across targets simultaneously; portfolio of candidates.
Key scores, affinity data, and competition metadata are recorded on-chain.
Failed submissions expose blind spots and high-variance regions in scoring models, which informs future fine-tuning and scoring calibration.
Risk Factors
NOVA is the brainpower behind compounds, but needs physical wet labs to progress. Wet-lab testing is expected to kick off end of Q1–Q2, closing the loop and enabling model stress-testing and fine-tuning.
Traditional pharma is already partnering with top AI labs. The decentralized alternative needs to prove it can compete.
Incentives introduce risks of gradient poisoning, gaming, and low-quality submissions.
Revenue requires licensing deals or screening-as-a-service contracts. Neither exists yet.
Outlook
Financial crime prevention (Yanez) and AI compute (Chutes) are large, established markets.
Drug discovery is something else entirely: $1.5T+ industry with a structurally broken pipeline, where a single breakthrough compound can generate hundreds of millions to billions in licensing revenue. The risk is real: drug discovery is hard, wet-lab validation is expensive, and the path from virtual hit to approved therapeutic is long.
Additionally, Metanova has signed an MOU with Yalotein Bio, a Shanghai-based biotech led by a Yale PhD, to test the top 50 nanobody candidates in the lab, adding a second modality (nanobodies) alongside small molecules.
The asymmetry is extreme.
4.4 SN3 – TEMPLAR
Building frontier models without frontier budgets

AT A GLANCE
Category: Pre-training.
Status: Covenant 72B training in progress (largest permissionless run ever).
Academic Validation: SparseLoCo accepted at NeurIPS OPT2025.
Current Gap: ~300x smaller than frontier datacenters.
Growth Rate: Decentralized training compute growing ~20x/year vs. 5x/year centralized.
Watch For: Covenant 72B final benchmarks, training-as-a-service revenue.
Strategic Positioning
Frontier model pre-training is increasingly concentrated. The compute required for state-of-the-art training doubles every 6 to 10 months, pricing out anyone but the major labs: OpenAI, Google, Meta, and a handful of others with billion-dollar GPU budgets. Templar is emerging as one of the most credible challenges to that concentration.
Subnet Context
Templar is a decentralized pre-training platform. Anyone can contribute GPU compute without whitelisting; a lower barrier to entry than other large-scale decentralized training efforts. Prime Intellect, Nous, and Pluralis all curate or gate their participants. Templar doesn't.
The team behind Templar operates across three subnets:
Templar (SN3, pre-training)
Basilica (SN39, decentralized compute)
Grail (post-training/RL)
This creates full-stack coverage of the model development pipeline.
Mechanism Design
The subnet run as a four-stage loop where compute, compression, validation, and incentives compound each training cycle.
![[share]](https://framerusercontent.com/images/IPvXMsWaMr6KTAFnnjqH06m5knA.png)
The subnet randomly assigns each miner a data portion ("page"), preventing gaming.
Miners train on assigned data and submit compressed gradients via SparseLoCo to shared storage.
Validators select the top 15 miners each round, whose updates merge into the shared model.
Training-as-a-service fees fund Covenant token buybacks, flowing revenue back to miners.
SparseLoCo is Templar's communication-efficient optimizer. It compresses gradients by ~97% while outperforming uncompressed baselines. In simple terms: it's the secret sauce for training over the internet, like sending a zip file instead of a raw folder, while getting better results than no compression at all.
Key metrics:
Compression: 1-3% sparsity + 2-bit quantization.
Performance: Outperforms DiLoCo (DeepMind) and DeMo (Nous) on loss and communication efficiency.
Practical impact: 72B parameter training over public internet with 6% communication overhead.
Competitive Landscape
Where Templar Stands Today
Decentralized training with permissionless participants produces essentially the same quality as centralized methods. The 1B parameter run: 20,000+ cycles, ~200 GPUs. Results show Templar-1B matching centralized baselines across HellaSwag, PIQA, and ARC-E.
![[share]](https://framerusercontent.com/images/EiYJ94AkUOW61YqSPkjNL3Kh40.png)
Covenant 72B, launched September 2025, is Templar's first attempt at frontier-relevant scale. At the first checkpoint, it outperforms all completed decentralized pre-training runs across measured benchmarks, making it the most powerful collaboratively pre-trained model to date.
Against K2 (centralized 65B, public checkpoints):
Sam Dare (Covenant AI founder) has publicly estimated the 72B model at ~60% of current top SOTA. Final benchmarks will be the real test.
How Fast the Gap Is Closing
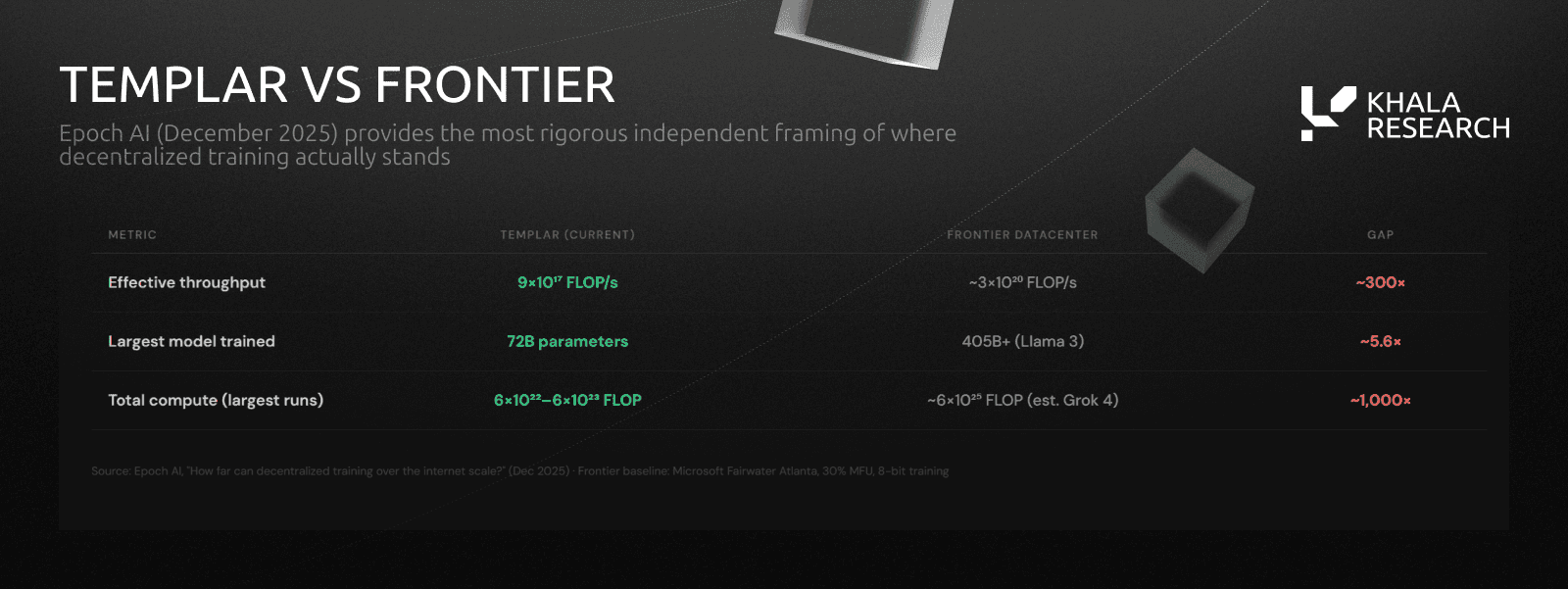
Templar is ~300x smaller than frontier datacenters in effective throughput. But decentralized training compute has grown 600,000x since 2020. Implying a ~20x per year growth rate, which dwarfs even the frontier AI training growth rate of ~5x per year.
If this trajectory holds, the gap narrows significantly within 2-3 years.
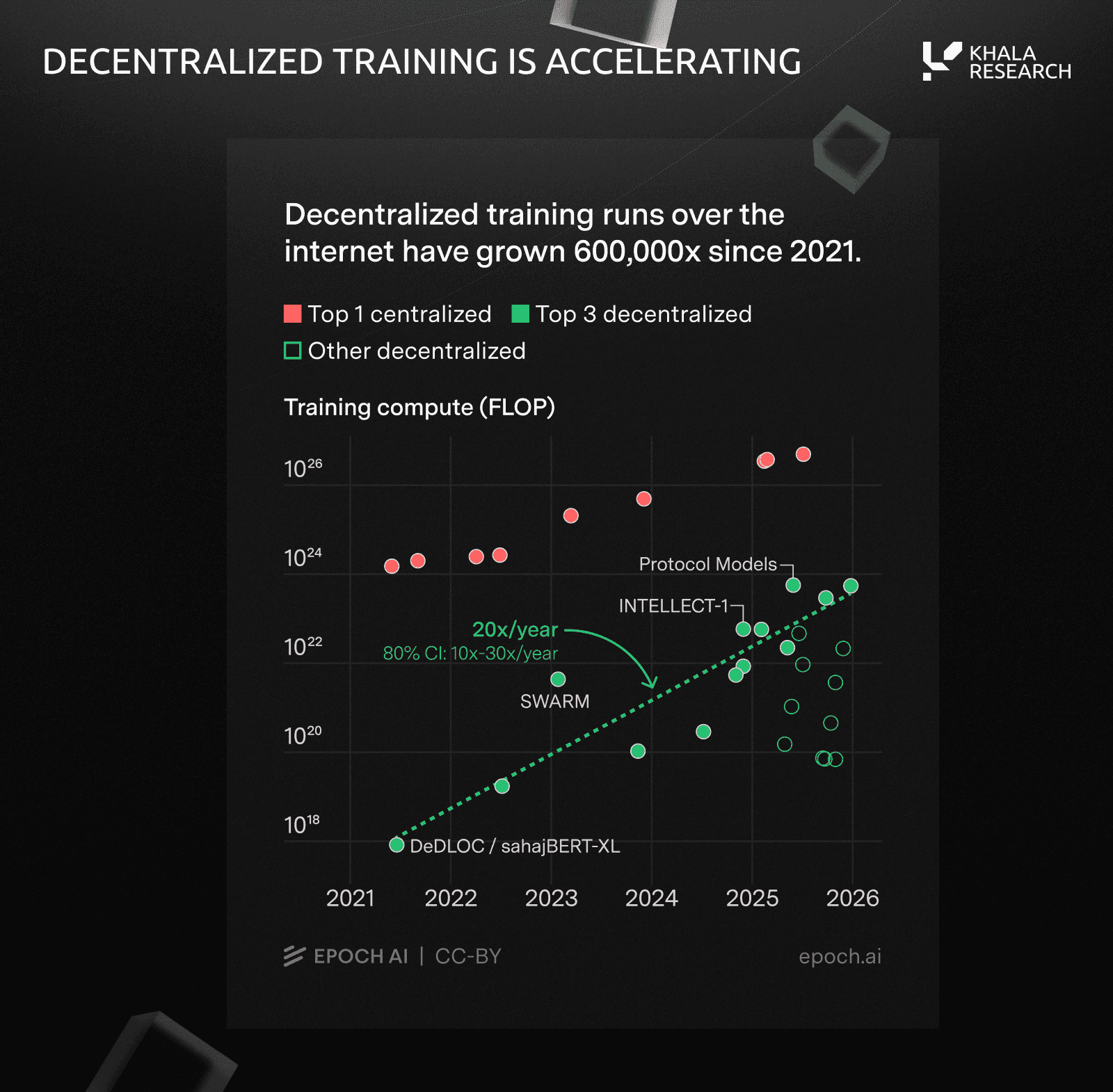
Epoch AI also notes that SparseLoCo's compression techniques could theoretically enable training models 8x larger than current decentralized runs, with streaming DiLoCo potentially adding another 10x reduction in bandwidth requirements.
Who Else Is Competing
Several well-funded projects pursue decentralized training: Prime Intellect (INTELLECT-3, 100B+ MoE, whitelisted, VC-backed), Nous Research/Psyche (Consilience 40B, $65M raised, $1B valuation, permissioned testnet), Pluralis Research (Protocol Model 8B, curated), and Gensyn (verification focus, VC-backed). All curate participants.
Templar is the only fully permissionless training in production.
![[share]](https://framerusercontent.com/images/EvVAYwZFgxpjZqZNerS8u9Z4.png)
Structural Advantages
Academic validation: Both SparseLoCo and Templar's Gauntlet reward mechanism paper were accepted at the NeurIPS OPT2025 Workshop; the first time research originating from the Bittensor ecosystem has been accepted at a major machine learning conference. This moves Templar's credibility from "crypto project claims" to "peer-reviewed research"; a meaningful signal for institutional evaluators.
Full-stack coverage: Operating across three subnets (pre-training, compute, post-training/RL) gives the Templar team vertical integration that competitors lack. Many decentralized training projects focus on a single stage of the pipeline.
Permissionless participation: While not unique to Templar, the absence of whitelisting or curation requirements means the network can scale compute contributions without bottlenecking on participant approval. This becomes increasingly important as decentralized training runs grow in size.
Revenue flywheel: 100% of training-as-a-service fees fund Covenant token buybacks, creating a direct link between commercial demand and miner incentives. This is a more sustainable incentive model than relying solely on TAO emissions.
Risk Factors
Scale gap: ~300x smaller than frontier datacenters in effective throughput. The trajectory is encouraging but not guaranteed to continue at 20x per year.
72B completion risk: If final benchmarks disappoint, it undermines the thesis of decentralized training at scale.
Compression tradeoffs: Scaling to 10,000 nodes could require 6x compute vs. centralized for the same performance. SparseLoCo mitigates but doesn't eliminate this.
Funding asymmetry: Prime Intellect and Nous Research/Psyche have raised significant venture capital (Nous $65M+). Templar still operates on TAO emissions and token economics.
Outlook
Templar's trajectory hinges on two milestones: completing Covenant 72B and the benchmark results. If the final model matches or exceeds centralized baselines at equivalent scale, the thesis is validated.
Catalysts to watch:
Covenant 72B final benchmarks.
Growth in training-as-a-service revenue.
Expansion of miner participation post-halving.
Continued academic validation.
Epoch AI data provides the macro tailwind: decentralized training compute is growing 4x faster than centralized infrastructure. Whether Templar captures a meaningful share of that growth depends on execution over the next 12 months.
4.5 SN64 – CHUTES
The number 1 Subnet on TAO; the inference layer that pays for itself

AT A GLANCE
Category: Inference.
Emissions Share: #1 subnet by emissions.
Revenue: $5.5M annualized (75% organic, 25% sponsored).
Throughput: 120B tokens/day, 34T+ lifetime.
Distribution: Top provider on OpenRouter.
Watch For: Organic-to-sponsored ratio trajectory.
Strategic Positioning
AI inference is where value gets captured. Training builds the model; inference is where it earns money. The global inference market: $116B in 2025, growing 17-19% CAGR toward $250-540B by 2030-2034. (Sources: MarketsandMarkets, Grand View Research, OG Analysis).
Subnet Context
Chutes is an open-source, decentralized compute provider for deploying, scaling, and running open-source models in production. They publish a live revenue dashboard, making it one of the most transparent revenue subnets in crypto.
![[share]](https://framerusercontent.com/images/xTLD2BtDVNYusvDEfmZu5FoB1M.png)
$5.5M annualized: 55% pay-as-you-go, 25% sponsored inference, 5% subscribers, 5% bounties.
Pay-as-you-go dominates, signaling genuine developer usage rather than marketing subsidies. But with 25% still sponsored, the organic-to-sponsored ratio is the key metric as Chutes matures.
Mechanism Design
Chutes operates a four-stage compute flywheel that converts GPU supply into developer revenue, with each cycle strengthening the next.
Miners register GPUs and deploy models as "chutes." Granite hardware fingerprinting verifies authenticity via CUDA stress tests. Developers send inference requests; miners compete to serve them, with the first miner to respond to cold model requests claiming the bounty. Validators audit fairness.
Revenue flows in as fiat; miners are scored on compute (55%), speed (20%), availability (20%), and bounties (5%) over rolling 7-day windows.
![[share]](https://framerusercontent.com/images/p9TtMshH2VUfu2YIKLbkqdmvhJo.png)
Throughput metrics show production-scale usage:
34+ trillion tokens processed (lifetime).
696k+ users (excluding OpenRouter), per Chutes' own reporting.
~120B tokens/day post-monetization (peaks at 160B).
~250x growth in the first 5 months.
50+ models supported across LLMs, diffusion, speech, and embeddings.
For context: OpenRouter (major LLM API aggregator, 5M+ developers, 60+ providers) processes ~1T tokens/day. About 20-25% of Chutes' daily volume (100B-120B tokens) flows through OpenRouter. Hyperscalers still operate at orders-of-magnitude larger scale.
These metrics represent actual compute being consumed by developers building real products. For context, OpenRouter, the major LLM API aggregator serving 5+ million developers, processes roughly 1 trillion tokens per day across all 60+ providers. 30B (20-25%) of the Chutes daily token volume throughput passes throughout OpenRouter.
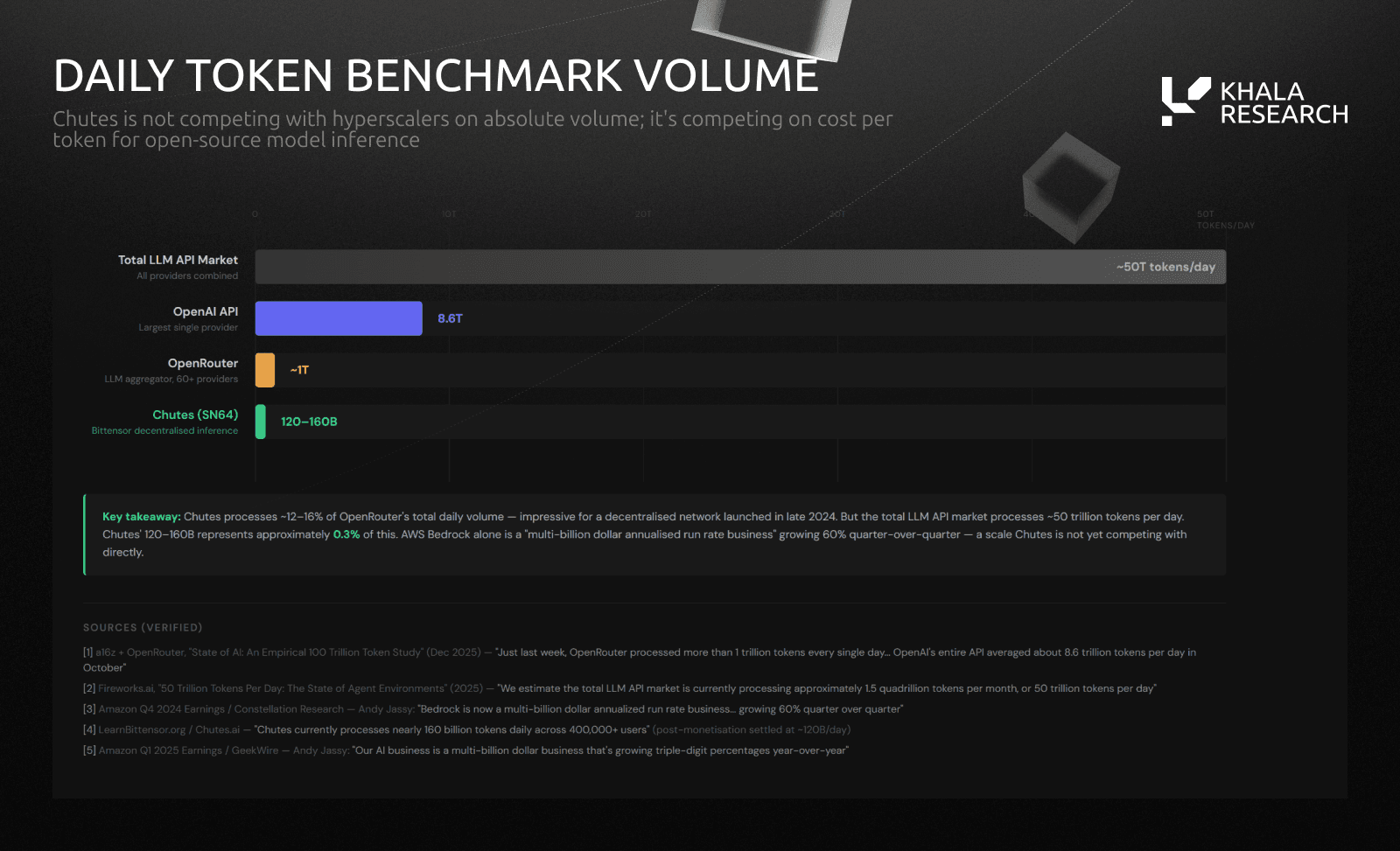
Competitive Landscape
Chutes competes in the serverless AI inference market against both centralized and decentralized providers, but the frequently cited "85% cheaper than AWS" claim requires context. Chutes primarily serves open-source model inference (DeepSeek, Llama, Qwen, Mistral), and the relevant comparison is against providers serving the same models, where pricing is competitive but not dramatically lower. The "85%" figure also depends on which AWS service you're comparing to (EC2 self-hosting vs. SageMaker vs. Bedrock) and which model.
Against hyperscalers, the cost advantage is structural: no data center leases, no enterprise sales teams, no AWS margins. Against specialized providers (Together AI, RunPod, DeepInfra), Chutes competes on price but isn't dramatically cheaper.
The real moat is the incentive-aligned supply side. Miners are economically motivated to provide compute through TAO emissions, creating a supply floor that centralized startups can't match without VC subsidies.
![[share]](https://framerusercontent.com/images/v7mjKPUn7vKSIZksup4WwkF6Vo.png)
![[share]](https://framerusercontent.com/images/fyjJT59lb8f8DLYjQwGcACMpzIc.png)
Structural Advantages
Top OpenRouter provider: Chutes ranks as the leading provider, giving it compounding distribution across millions of developers.
First-mover on new models: Chutes has consistently been among the first providers to offer newly released open-source models (DeepSeek V3, Kimi K2), which drives developer trial and sticky usage patterns.
Composable by design: Every model is a native API endpoint, making Chutes natural backend infrastructure for AI agents. Centralized providers are slower to offer this optionality.
Structurally lower costs: TAO emissions subsidize the supply side, creating a cost floor VC-funded competitors can't match without continued fundraising or margin compression.
Risk Factors
Validator concentration: The main validator is operated by Rayon Labs (~16 H200 GPUs). Single-operator dependency.
Revenue quality: 25% is sponsored inference so user fees are subsidized. Real organic revenue may be lower than headline figures suggest.
Inference commoditization: Together AI, RunPod, Fireworks are racing to zero. Margins will compress across the board.
Model pricing pressure: Loss-leader pricing from models like DeepSeek may compress margins further.
Outlook
$5.5M annualized is modest against centralized providers, but it's the strongest revenue signal in Bittensor. The scale isn't there yet but the trajectory is.
Catalysts to watch:
Organic-to-sponsored revenue ratio. A shift toward 70%+ organic would validate the demand thesis.
Continued ranking as top provider on OpenRouter and expansion to additional aggregators.
Adoption as backend inference infrastructure for autonomous AI agents.
The central question is whether the incentive-aligned supply side, the one thing centralized competitors cannot replicate, translates into a sustainable moat or gets overwhelmed by VC-backed competitors racing to the price floor.
5. CATALYSTS AND RISK FACTORS
The investment case for TAO and its subnet ecosystem hinges on a series of near-term catalysts and identifiable risks.
The disconnect creates potential asymmetry for investors who believe decentralized approaches can capture meaningful share of the AI infrastructure market.
TAO-specific catalysts: Institutional capital entering (>$170M across Yuma Funds, Grayscale ETF, Deutsche Digital Assets ETP), TAO halving creating supply shock.
Subnet catalysts: Chutes revenue trajectory and organic-to-sponsored ratio, SCORE and MIID contract renewals and ARR disclosures, Templar 72B training completion and benchmark results, NOVA wet-lab validation beginning Q1-Q2.
Risks to monitor: Subnet competition from centralized AI labs, TAO inflation pressure not offset by subnet expansion from 128 to 256 increasing liquidity fragmentation.
6. CLOSING THESIS
The five subnets covered in this report span inference compute, computer vision, regulatory compliance, drug discovery, and model pre-training. What they share is a structural advantage that centralized competitors cannot replicate: token-incentivized competition that compounds quality over time.
We're not naive about the gap between early traction and sustainable commercial scale. This report profiles 5 out of 128 subnets. Not all will succeed. But the ones generating revenue, signing enterprise contracts, and passing academic peer review are no longer experiments; these are early-stage AI businesses operating on infrastructure that gets stronger the more it's used.
Today, centralised AI labs collectively command valuations above $1 trillion. OpenAI alone is valued at $500 billion, with reports of a $730–830 billion raise and an IPO filing for H2 2026.
TAO's fully diluted valuation sits at approximately $4 billion (as of Feb 2026), roughly 1/125th of OpenAI alone.
The question has shifted. It's no longer whether decentralized AI can work. These subnets are showing it can.
Now the question is how much of the market they capture.